This is the 2nd post in my “knowledge portal architecture” series. See the first article and introduction here
Pride In Performance – Which Performance?
Imagine you ask a young, nerdish developer what’s the most important goal of his efforts in coding. What would be his answer? I would bet that the majority would go for ‘Performance’. When you think about large-scale big data systems, the first major challenge that comes to mind is how would one handle such enormous amounts of data and still be able to provide a reasonable performance, measured in processing time. There are 3.7 million videos uploaded to YouTube daily, but when you upload a video there, you only care about the one you have uploaded, and you expect to see it online in a reasonable time. And when you search Google, you expect a result to be returned within So processing performance is of extreme importance.
But there’s another kind of performance that is often overlooked and has an equal, and sometimes even greater importance. How fast can the development team develop and deploy a new feature? When we say ‘develop and deploy’ we obviously imply that the team needs to make it in a way that would not introduce any new bugs and keep the system stable and running. In other words, how does one maintain decent team performance?
The role of any software architect, VP of R&D, and in fact, any developer, lies in the tension between these two types of performance. We need to develop a system in a timely fashion, that would run reasonably fast, and be flexible enough to accept ongoing development. There’s no silver bullet for that, and every system is different, but still, the industry has treaded constant evolutionary paths all aim to improve these two goals. The processing performance usually is improved by Moore’s law and faster hardware – faster CPUs, faster memory units, more parallelism in GPUs. Making the team perform faster, on the other hand, needs practices like what I’m about to describe in the next part of this limited series.
The micro-services bus
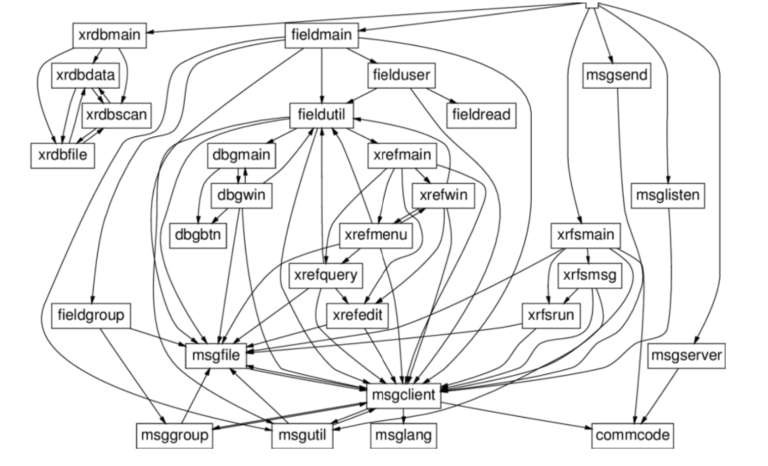
 Indeed the major development that aims to improve what happened in recent years is the shift to micro-services. The need is to build a loosely-coupled system, which means that a break in one system, will stay in that system. A bug, a machine failure, a third-party error – nothing will affect the others. Much like your home fuse box: if one room goes black, the rest can still shine.
Indeed the major development that aims to improve what happened in recent years is the shift to micro-services. The need is to build a loosely-coupled system, which means that a break in one system, will stay in that system. A bug, a machine failure, a third-party error – nothing will affect the others. Much like your home fuse box: if one room goes black, the rest can still shine.
Isn’t that simple to solve? We can just split the huge code base that we probably have into smaller pieces, maybe along business lines. For example – the user manager module, the pricing module, the search module, and So on. The problem is, that a simple split of a monolithic app into microservices is not the whole story. That is easy. The bigger question is how will these modules work together. How will they communicate with each other?
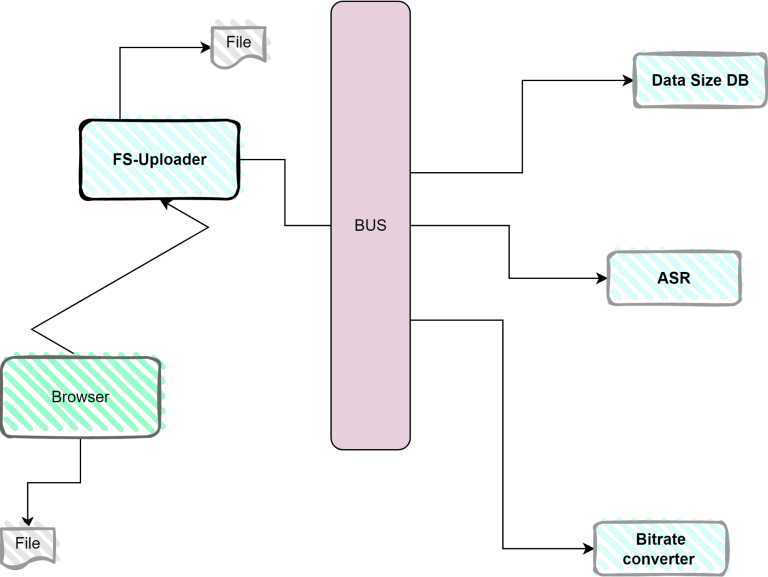
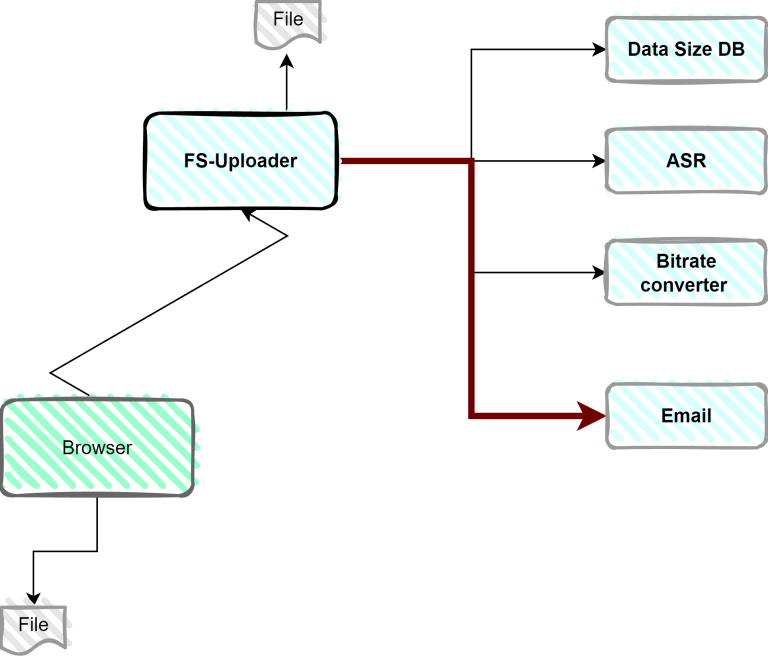
For example, take the most basic event in Korra’s system – a new tutorial video was uploaded to the system by the admin, in our case, the knowledge manager. There’s a microservice that is responsible for the upload operation, called, in our case, the FS-Uploader. It runs on the backend, waits with an exposed API for upload calls from the browser, and saves the file to the disk.
Then, once the upload is done, several other operations should be performed. For example, the audio in a / video needs to be recognized and transcribed into text, so that it will be searchable. The video should be converted into various bitrates so that users with low bandwidth – for example, mobile users – can watch it without stutters. We also need to save information about its size so that we can charge users by the amount of data they use.
In a regular system, we might be tempted to call 3 kinds of services once the file has been uploaded:
- Call the Automatic Speech Recognition service on the file
- Convert the video into multiple bitrates
- Save its size into a database