
The (underestimated) ingestion element of RAG
Korra was founded ages ago, before the “Revelation” of ChatGPT 3.5. It’s hard to believe it’s been over three years! Back then, when generations were still counted in alphabet letters and not in tokens, we were an enterprise search company with a slogan: “Answers. Spot On”. We had a tough time convincing clients that we could do it. Then, in Q4 of 2022, came ChatGPT and pushing RAG strongly under our feet, and everything started to click. Finally, organizations realized the power of an AI knowledge base.
Now, in a world with RAGs stretching as far as the eyes can see, what makes Korra so unique? We have a growing list of formidable clients. What makes them trust a small startup with a weird double-R name?
Rich documents
Korra developed an AI knowledge base platform, with a focus on documents. Specifically, we help users get answers from technical industrial documents. The industries may vary, but their documents share many common characteristics. They are usually page-rich documents, often structured in a certain way. Indeed, each company and department maintain their own style, but we’ll usually see chapters, titles, subtitles, page headers and footers, an acronym list, a Table of Contents and sometimes – for those knowledge managers with the least faith in enterprise search – they even have an Index.
Not only do these documents carry the same characteristics when it comes to form, they also feature many common types of elements. They all have diagrams, figures and lists. Lists of steps, lists of items, lists of instructions. Bulleted lists and numbered lists. And tables, too, come in many styles: some have borders to delineate the cells. In others, cells are separated by spaces and indentations. Some have a simple structure – just rows and columns – while others merge some cells to have an unbalanced structure. One cannot stop being amazed by the almost artistic creativity of table authors.
The content of technical documents also shares many similarities. How can we not talk about the Warnings, with some exclamation icon or other tools to scare the reader. You’ll also glaze over the legal sections, always well written but never read. There are version numbers, too. Created By, Updated By. And the list goes on.

Fig. 1: an example of a page from a technical document
Technical documents in an AI knowledge base carry more than text
All those features allow documents to carry much more information than just their text. While LLMs excel at understanding and producing text, technical documents, with all their extra information, pose a more difficult challenge. It’s also very important for safety reasons: technicians need to look at the vetted source documents, minimizing the danger of acting based on innovative hallucinations.
RAG systems do not use the knowledge that LLMs learned, or its “parametric knowledge”. They use the LLM’s understanding and reasoning power. It means that the Retrieval part of RAG is the most important element: the system is only as good as its retriever. And that’s the first reason we do so much pre-processing of these documents: the engine has to understand them in order to achieve accurate results at the retrieval phase.
To present a document to the LLM and receive an answer, we can’t upload it as-is: it’s too big. Not only is it too big, it might also take too much time. Second, even with the latest large-context LLMs, accuracy improves when context is more concise. So, we need first to cut the text into sections, and then use these.
How can that be done? The simplest way would be to cut the document by its pages. But a paragraph might start on one page and end in the next, so we would index two segments, one without an end and one without a beginning. That would confuse the engine, so we do something else. We cut it by paragraphs and titles.
Everyone knows a “paragraph” or a “title” when they see one, but PDF documents don’t necessitate any special tags to differentiate a title or a paragraph. PDF is first and foremost a graphics format. For all it cares, there are a bunch of characters with x and y coordinates for the PDF viewer to place on the page. So, the first task is to identify every element on the page.
We pass each document through a visual-semantic AI model that identifies each element based on its content and layout. We then analyze the titles and determine the hierarchy – which title is Heading 1, which one is H2, and find the title path that led the reader to this paragraph. Only at this point can we tell a full story: as per the example in Fig. 2, this is a paragraph about “Min, Max and Center adjustment” in the “I/O Configuration and Operation” chapter. Note that the chapter name is not even on this page: the algorithm carries it from a few pages back.
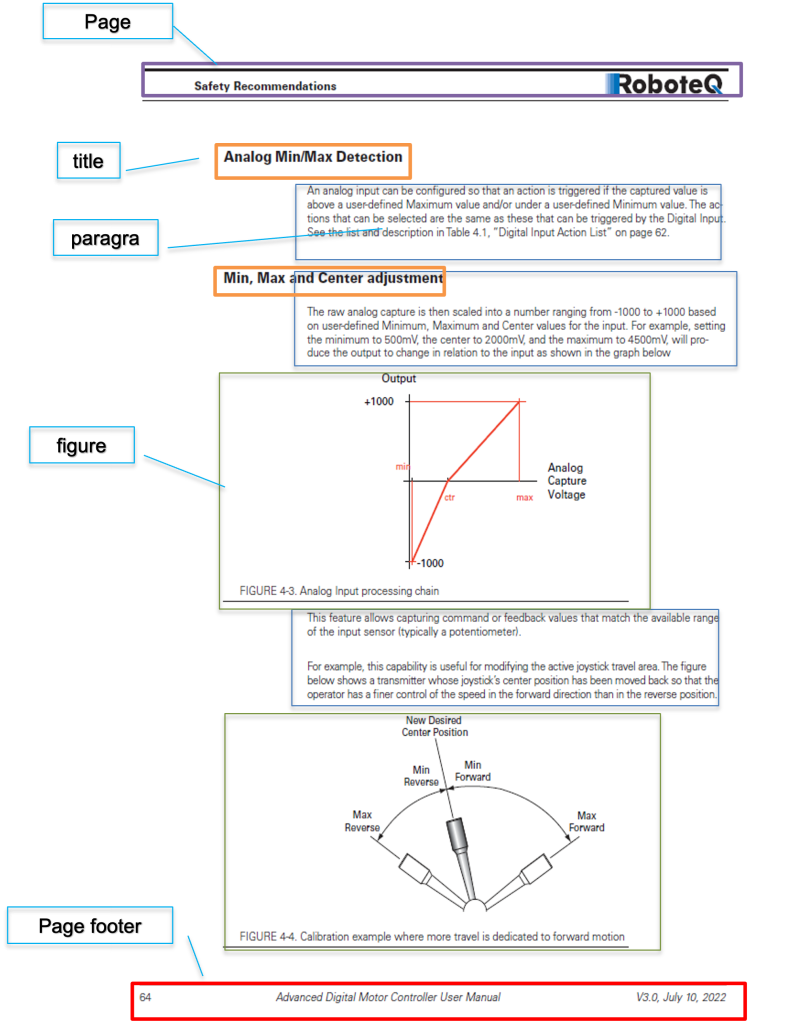
Fig. 2: layout and element identification in Korra
Once we identify the elements, we decide how to index them in the search index. We use the title path for every paragraph, and we also consider the reading flow in 2-column documents (Fig. 3) and in presentations. We also need to know what not to include in the search. Page footers, for example, are useless: no one cares about the copyright notice or the page number.

Fig. 3: A 2-column layout
Figures are interesting beasts. They usually have a title in the format of “Figure X: title text” or something similar. We extract these figures, connect them with their title, put them in context and locate the references to this figure even if this reference is on a different page. We analyze the picture, too, and convert it to text so it is searchable. We could be using OCR but these days there’s a far better method: an LLM can describe it.
Finally come the tables. Once an element is identified as a table – not always an easy task – we need to convert it into natural language to make it searchable in semantic engines. For example, in the table below (Fig. 4), the 0.32 number really means “the normal electric quantity in kWh, when testing electricity at Meter 2, should be 0.32”. That’s why tables are so popular: they can present the same information in a much more compressed way than natural language.
“But why should I care?”, one might ask. After all, since the Revelation, we can just throw tables at LLMs to get perfect answers to any question. Again, that’s the R in RAG: we need first to retrieve these tables. But semantic engines need natural language, so what do we do?
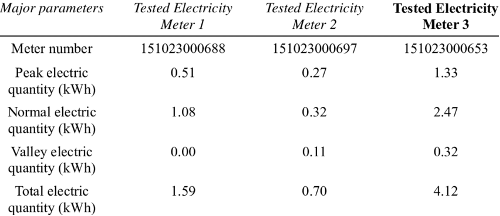
Fig. 4: A simple table
The solution is simple: an algorithm converts a table to a paragraph of natural language, which search engines can process. We do that both for simple tables as the one in Fig. 4, as well as for more complex ones, where some cells are merged and used for several rows or columns, as in Fig. 5. For such tables, it is imperative not only to identify the table itself, but also to analyze its cells and the relationship between them.
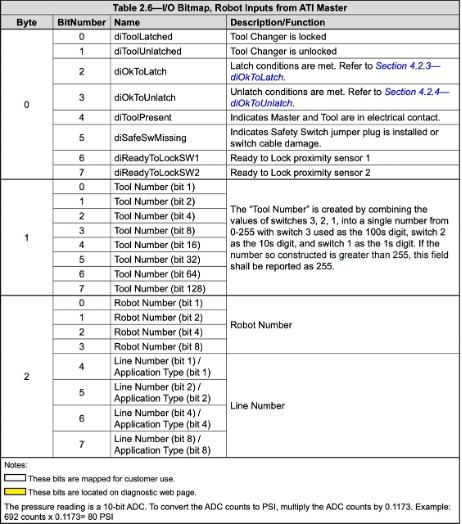
Fig. 5: A complex table
Only after using this analysis, we can answer questions about the bits of the robot inputs.
Fig. 6: a complex table, analyzed
Better accuracy at detection translates to better answer accuracy, as seen in the table above.
Accuracy is not enough
Why do we need all that? Getting the right answer is one critical goal. But the other critical goal is getting to the right answer. Since these documents are much more than their text, it is imperative to transfer the user smoothly into them, directly to the paragraph, diagram or table where the answer lies.
From analyzing the document, we know exactly the coordinates of each element. When engaging with the AI knowledge base, once a user clicks on the search result, or reference, the document will open within Korra’s document viewer with the element highlighted.
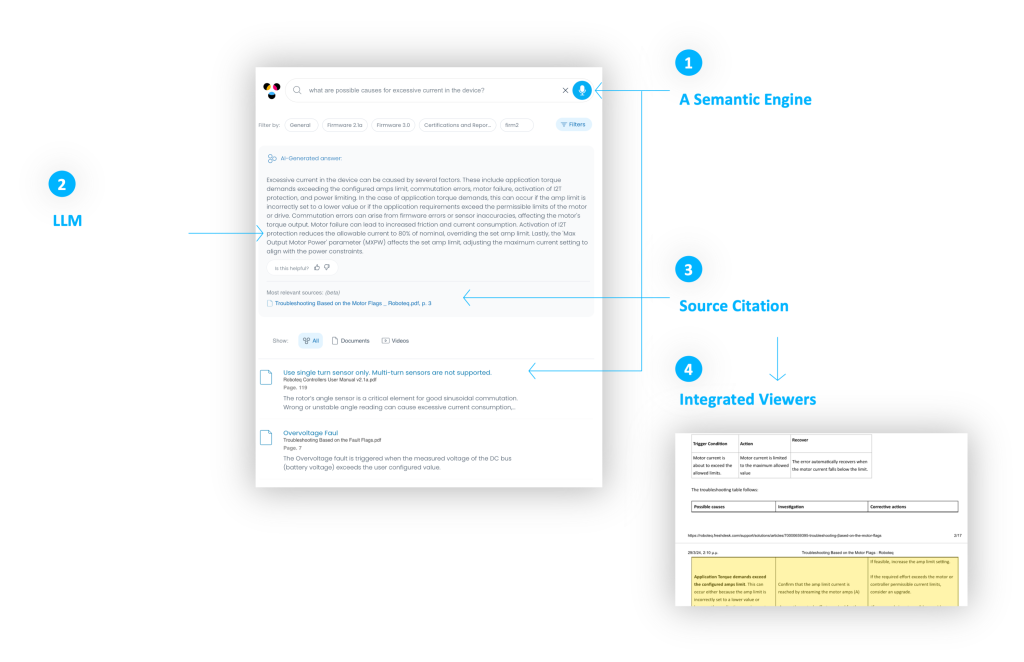
The long way from RAGs to Riches
As we have seen, RAG is a great foundational technique, but it must be supplemented by an array of pre- and post-processing modules before and after it runs its magic.
From layout analysis, to element identification, to content hierarchy, paragraph segmentation and cell extraction, all these steps serve as the basis on which runs a retrieval engine that will get the answer to the user and vice versa.
The result? A powerful, accurate AI knowledge base that unleashes the latent power within internal repositories, and converts them into game-changing actionable insights.