
The architect's cut
This is the third part in my ongoing series about how to build a knowledge portal platform, from the software architecture perspective. Read the previous part here.
Horizontal scaling
One of the proclaimed advantages of microservices is the ability to scale horizontally. All we need to do is to add more machines, run a microservice on each, and the system could elastically process more data as needed. The pub-sub mechanism facilitates that, too: when you need to send a message to a processor service, you don’t need to know which service instance it is. Just put it on the bus, and the available service will pick it up and work on it. If there are a few services of the same kind, that’s ok.
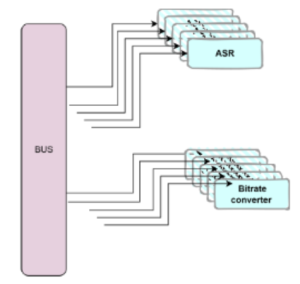
But that’s not enough. This type of simplified scaling would help with CPU bottlenecks when the main thing the code is doing is computation. Very few applications, like games and AI, have computation as the main task. For backend systems, services usually do very little computation and then read or write stuff in a database.
In such case, even if we multiply the microservices, it won’t help us with the database bottleneck:
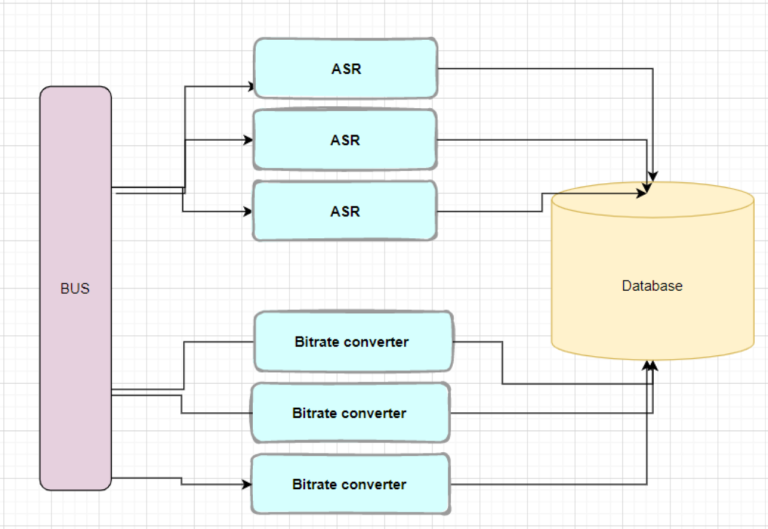
Here’s a real scenario. As explained, when a tutorial video is uploaded to the system, it goes through the bitrate conversion that allows slow mobile video players to show it without stuttering. However, that process takes time – sometimes even several minutes. While this process is happening, we still want to allow users to watch the original video, until the bitrate conversion is completed.
If we use the classic, single-database design, we’d have to maintain a video_sources collection (if we use MongoDB) or table (if we use a SQL database). Upon upload, the FS-Uploader would update this collection with the location of the original video, and the Bitrate Converter would update it with the transcoded video. For example:
Video_sources: [{
Id: “9344-dfda-4444-123d”,
original_file:”http://cdn.korra.ai/videos/my_video_name.mp4”,
multi_bitrate_file:”http://cdn.korra.ai/transcoded_videos/my_video_name.hls”
} ,{
Id: “1234-45678-5454-3333”,
original_file:”http://cdn.korra.ai/videos/anothervideo_name.mp4”,
multi_bitrate_file:”http://cdn.korra.ai/transcoded_videos/anothervideo_name.hls”
} …]
What would happen if we want to deploy more instances of FS-Uploader and/or Bitrate Converter? The instances would get multiplied alright. But the database would have to remain singular, as both types of services need to update it. A clear bottleneck and source for trouble.
Breaking the bottleneck
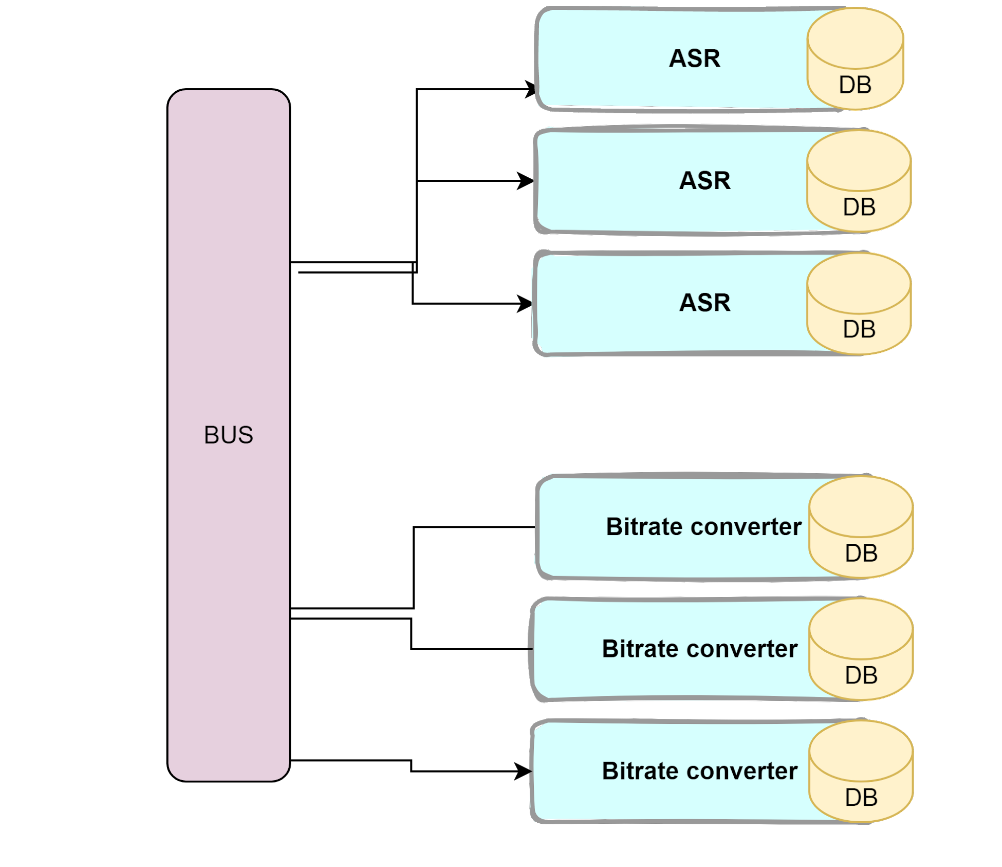
The solution is startlingly simple. Multiply the database, too! Have a dedicated database inside each service. When we first heard of this idea, it sounded crazy. Can it work?
Then, we’d have two collections:
Original_video_sources: [{
Id: “9344-dfda-4444-123d”,
original_file:”http://cdn.korra.ai/videos/my_video_name.mp4”,
} ,{
Id: “1234-45678-5454-3333”,
original_file:”http://cdn.korra.ai/videos/anothervideo_name.mp4”,
} …]
And
Converted_video_sources: [{
Id: “9344-dfda-4444-123d”,
multi_bitrate_file:”http://cdn.korra.ai/transcoded_videos/my_video_name.hls”
} ,{
Id: “1234-45678-5454-3333”,
multi_bitrate_file:”http://cdn.korra.ai/transcoded_videos/anothervideo_name.hls”
} …]
And we make sure to wire the API that is exposed to external clients, to each of the services. The architecture would look like this:
On any decision we take, we have a tradeoff. What is it here?
First, there’s storage. We have the actual space the database installation takes – but that’s really something constant – meaning, it doesn’t grow according to the amount of users. What is proportional to the number of users is ID. In this example it looks really small, but the principle is the same: when we multiply the number of databases, we introduce redundancy into the system. There would no longer be a ‘single source of truth’. The same data items would appear in multiple locations.
These days, storage is cheap. Man hours, on the other hand, are expensive. Very expensive. A design that would allow less bugs, due to the decoupling, and would offer scalability in a very simplistic manner, is the winner.
Second, it requires more work to start and provision each microservice, because of the need to add a database to it. So it’s good to note that a one time effort of making a small container image with MongoDB or MySql is definitely worth the while. If we don’t want that, we can opt for a half-way solution. We can design the architecture so that it would be easy to separate it later. We can make a rule and let every developer know about it: one collection (or table, in relational databases) per service. When starting to develop we didn’t really provision a separate database for each microservice. We did the restriction by collection, and enforced the separation through explanations and code reviews. I have to say that I wish we would go the full mile. Under the pressure of sprints and scrums, and without the full picture always available, developers would create shortcuts that are not always inline with your vision as an architect.
Talking about rules, we did create another rule that goes hand in hand with the separation of databases. It’s called “clean after yourself”. Using the pub-sub mechanism, each microservice subscribed to delete events like DeleteDocument, DeleteKnowledgeUnit and the like. When such an event is published, all modules that have subscribed to it, receive the message and delete.
Working with documents over a bus
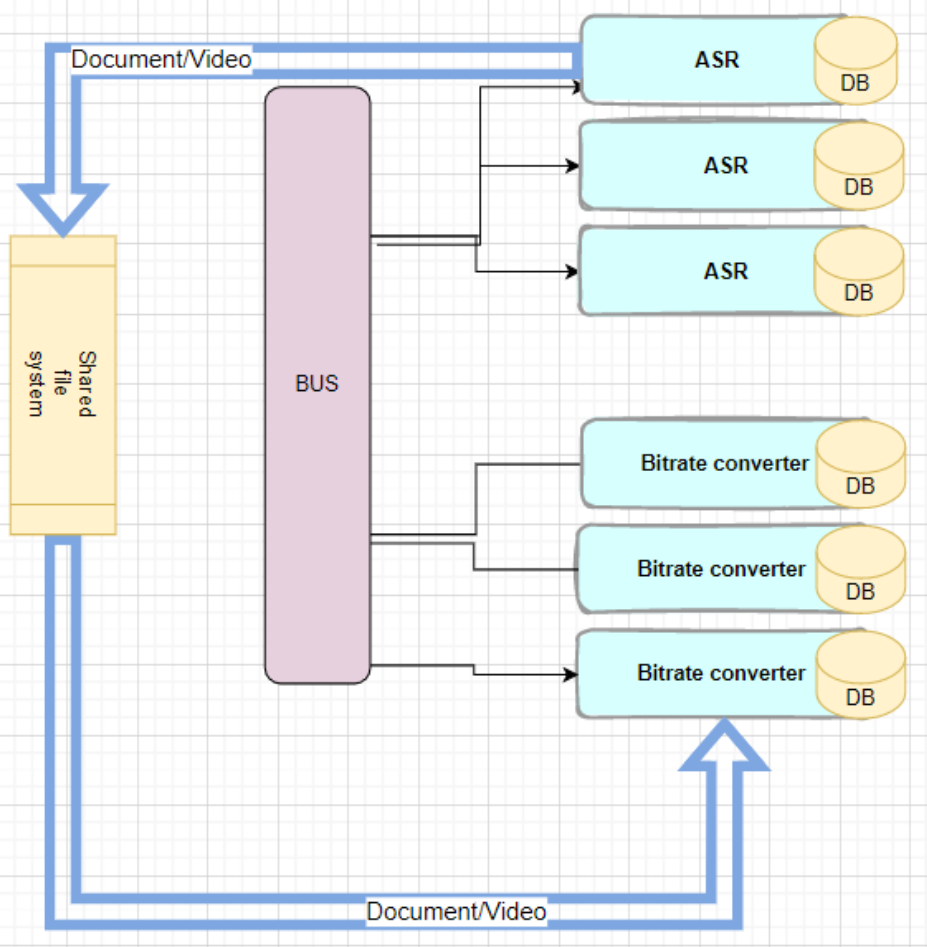
When building a document-centric knowledge portal like Korra’s, we have another challenge that does not always present itself in other systems. Documents and video tutorials are big, so we can’t just embed them in a message and publish them as-is to the bus. We need to find another way.
The obvious, simplest solution is to use a shared file system, and that’s what we did. We chose GridFS, from MongoDB’s suite. Every time we need to pass a big file between the modules, we’d write the file to GridFS, get a unique ID, and put it on the message that’s published on the bus. The subscriber would get that ID and retrieve the file to work on:
Summary
We were presented with the challenge of building a large-scale system for document management, knowledge portal and search engine. The buzzword of the era is microservice. But what does that really mean?
We decided to go with:
- A bus-centric system, where no microservice calls another
- A distributed database, where each microservice maintains its own state
- A shared file system for passing large files between the microservices
We made one other major decision: do not attach yourself to one hosting platform, like AWS or GCP. Remember that knowledge bases – especially internal ones – hold all of the intellectual property of the company. So we have to make sure that we can provide an on-prem solution, safe and secure. In addition, we want to be able to select a provider based on other factors, like price. But on that, in another article